Llama 3:Meta 的新一代開源大型語言模型
本篇旨在介紹 Meta 最新發布的 Llama 3 大型語言模型系列 ,包括 8B 和 70B 參數的預訓練及指令微調模型。
目錄
架構與訓練細節
核心架構:採用標準的「僅解碼器 (decoder-only)」Transformer 架構。
詞彙量與序列長度:詞彙量為 128K 個 Token,並在 8K Token 的序列上進行訓練。
注意力機制:應用了「分組查詢注意力 (Grouped Query Attention, GQA)」。
訓練規模:在超過 15T 個 Token 的數據上進行預訓練。
後訓練:包括監督式微調 (SFT)、拒絕採樣 (rejection sampling)、近端策略優化 (PPO) 和直接偏好優化 (DPO) 的組合。
效能表現
超越同級模型:
-
Llama 3 8B(指令微調版)的性能優於 Gemma 7B 和 Mistral 7B Instruct。
-
Llama 3 70B 廣泛優於 Gemini Pro 1.5 和 Claude 3 Sonnet。
-
在 MATH 基準測試中,Llama 3 70B 略微落後於 Gemini Pro 1.5。
來源:Meta AI

預訓練模型:在 AGIEval(英語)、MMLU 和 Big-Bench Hard 等多個基準測試中優於其他模型。
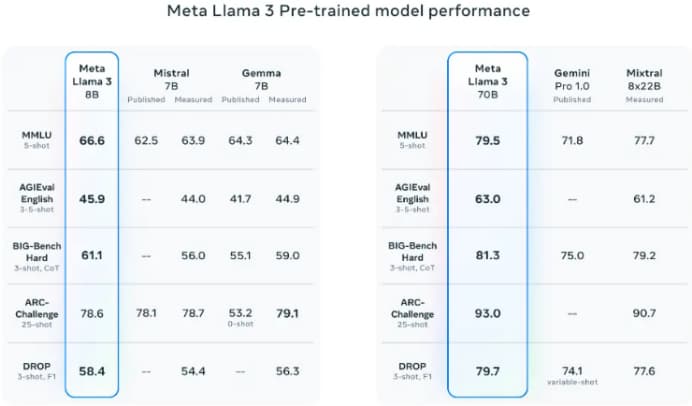
來源:Meta AI
未來展望
Llama 3 400B:Meta 報告稱將發布一個 400B 參數的模型,該模型仍在訓練中。

來源:Meta AI
多模態與多語言支援:未來計畫還包括多模態支援、多語言能力和更長的上下文窗口。
許可證:Llama 3 模型的許可資訊可以在模型卡上找到。
Llama 3 的詳細評測

結語
Llama 3 系列代表了 Meta 在開放語言模型領域的最新進展,在不同規模下均展現出強勁的競爭力。特別是 Llama 3 70B 在多項基準測試中超越了其他領先模型。憑藉其高效的 Transformer 架構和大規模的預訓練數據,Llama 3 為開源 AI 社群提供了高性能且靈活的基礎模型。未來對多模態和多語言支援的投入,預示著 Llama 3 將在更廣泛的應用中發揮重要作用。
References
上一篇:Models - LLaMA
下一篇:Models - Mistral 7B