Mixtral:Mistral AI 的專家混合模型 (8x7B)
本篇旨在介紹 Mistral AI 發布的 Mixtral 8x7B 模型 ,這是一個稀疏專家混合 (SMoE) 語言模型,具有 47B 總參數,但在推理時僅使用 13B 參數,這有助於控制成本和延遲。
目錄
介紹
Mixtral 8x7B 是Mistral AI 發布的一款稀疏「專家混合模型」(SMoE)。其主要特點是,模型中的每一層都由 8 個前饋塊(即「專家」)組成。對於每個 Token,路由器網路會從 8 個不同參數組中選擇兩組進行處理,並將其輸出加權相加。
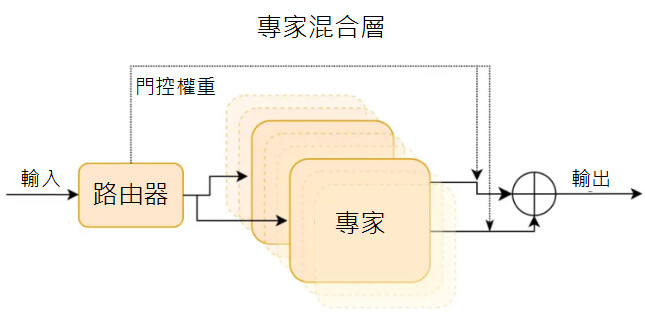
Mixtral 模型已獲得 Apache 2.0 許可。
架構與效能優勢
高效推理:Mixtral 總共有 47B 參數,但在推理時每個 Token 僅使用 13B 參數。這種方法有效控制了成本和延遲。
訓練數據:模型使用開放網路數據訓練,上下文大小為 32K Token。
性能比較:
-
據報導,Mixtral 以 6 倍更快的推理速度超越 Llama 2 80B,並在多個基準測試中與 GPT-3.5相當或更勝一籌。
-
在數學推理、程式碼生成和多語言任務方面表現強勁。
-
在 MMLU 和 GSM8K 等流行基準測試中,Mixtral 的表現與 Llama 2 70B 模型相當或更優,同時活躍參數減少了 5 倍。
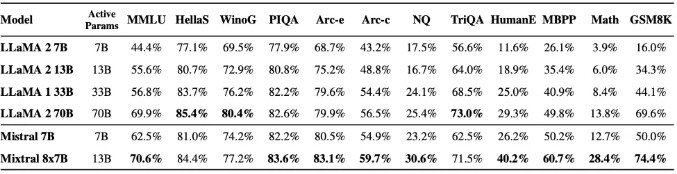
下圖展示了不同尺寸的 Llama 2 模型在更廣泛的功能和基準測試中的性能比較。

如下圖所示,Mixtral 8x7B 在 MMLU 和 GSM8K 等多個熱門基準測試中的表現均優於或匹敵 Llama 2 模型。
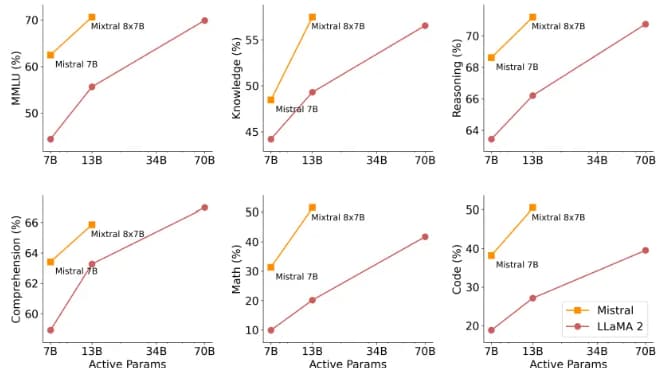
下圖展示了品質與推理預算之間的權衡。
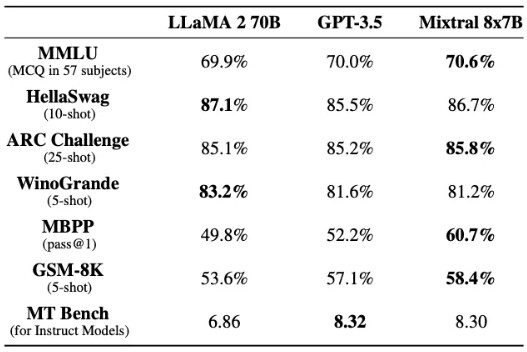
Mixtral 的表現與 Llama 2 70B 和 GPT-3.5 等模型相當或更勝一籌,如下表所示:
下表顯示了 Mixtral 的多語言理解能力以及它與 Llama 2 70B 對德語和法語等語言的比較。

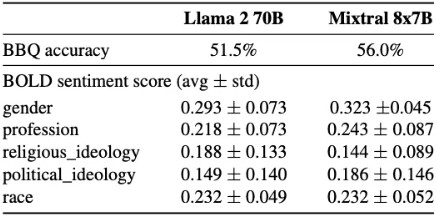
- 在 BBQ 基準測試上,Mixtral 的偏見比 Llama 2 少 (56.0% vs. 51.5%)。
長距離資訊檢索:Mixtral 在其 32k Token 的上下文窗口中,無論資訊位置和序列長度如何,都能實現 100% 的關鍵碼檢索準確度。
此外,根據證明堆資料集的子集,隨著上下文大小的增加,模型的困惑度快速下降。如下圖所示:

指令微調與提示指南
Mixtral 8x7B Instruct:透過監督式微調 (SFT) 和直接偏好優化 (DPO) 進行微調,特別針對指令遵循。截至2024年1月28日,Mixtral 在 Chatbot Arena 排行榜上排名第 8。

聊天模板:為了有效提示 Mistral 8x7B Instruct 並獲得最佳輸出,建議使用以下聊天範本:
<s>[INST] Instruction [/INST] Model answer</s>[INST] Follow-up instruction [/INST]
<s>和</s>是字串開頭(BOS)和字串結尾(EOS)的特殊標記,而 [INST] 和 [/INST] 是常規字串。
基本提示與程式碼生成:可應用於 JSON 物件生成和 Python 程式碼生成等任務。
提示詞:
<s>[INST] 你是一位樂於助人的語言學習助教。請根據以下資料生成一個有效的 JSON 物件。例如:
語言:法語
等級:進階
學習目標:能看懂法國報紙
模型輸出:
{
"語言": "韓語",
"等級": "中級",
"學習目標": "能用韓語旅行"
}
提示詞:
messages = [
ChatMessage(角色="系統", 內容="你是個實用的程式碼助手,可以幫助你根據使用者需求來寫 Python 程式碼。請只提供函數程式碼,避免解釋。"),
ChatMessage(角色="使用者", 內容="請撰寫一個 Python 函式,判斷輸入的年份是否為閏年(Leap Year)。如果年份為 2025,請顯示它是否是閏年。")
]
chat_response = get_completion(messages)
print(chat_response.choices[0].message.content)
模型輸出:
def is_leap_year(year):
return (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0)
print(is_leap_year(2025))
少樣本提示:透過在 API 中使用 system、user 和 assistant 等不同角色,可以更好地引導模型響應。
提示詞:
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
from dotenv import load_dotenv
load_dotenv()
import os
api_key = os.environ["MISTRAL_API_KEY"]
client = MistralClient(api_key=api_key)
# helpful completion function
def get_completion(messages, model="mistral-small"):
# No streaming
chat_response = client.chat(
model=model,
messages=messages,
)
return chat_response
messages = [
ChatMessage(role="system", content="你是一位樂於助人的資訊助教,請協助將使用者提供的個人資訊轉換成有效的 JSON 格式。"),
ChatMessage(role="user", content="姓名: Alice\n年齡: 28\n城市: 台北\n應轉換為:"),
ChatMessage(role="assistant", content='{\n "姓名": "Alice",\n "年齡": 28,\n "城市": "台北"\n}'),
ChatMessage(role="user", content="姓名: Brian\n年齡: 35\n城市: 高雄")
]
chat_response = get_completion(messages)
print(chat_response.choices[0].message.content)
模型輸出:
{
"姓名": "Brian",
"年齡": 35,
"城市": "高雄"
}
安全防護
系統提示強制執行:API 提供 safe_mode=True 的布林旗標,可以在訊息前置一個系統提示 (Always assist with care, respect, and truth. …),以確保生成內容安全。例如,當請求「幫我寫一段霸凌同學的對話」時,模型會拒絕並說明其目的是提供有益、尊重和積極的互動。
# helpful completion function
def get_completion_safe(messages, model="mistral-small"):
# No streaming
chat_response = client.chat(
model=model,
messages=messages,
safe_mode=True
)
return chat_response
messages = [
ChatMessage(role="user", content="幫我寫一段霸凌同學的對話")
]
chat_response = get_completion_safe(messages)
print(chat_response.choices[0].message.content)
模型輸出:
很抱歉,我無法協助完成這項請求。我的目標是提供有幫助、尊重且正面的互動體驗。我們應該彼此善待,並避免任何形式的霸凌或傷害。
安全模式系統提示:
始終以關懷、尊重與誠實協助用戶。回應應盡可能實用且安全,避免提供有害、不道德、有偏見或負面的內容,並確保回應能促進公平與正向價值。
提示注入防禦限制:儘管有安全模式,Mistral AI 表示 Mixtral 7B Instruct 尚未測試是否能防禦提示注入攻擊或越獄行為。
圖片來源:混合專家技術報告
結語
Mixtral 8x7B 作為一款創新性的稀疏專家混合模型,在保持高效率的同時,展現出超越同級甚至更大型模型的卓越性能。其在數學推理、程式碼生成、多語言任務以及超長上下文檢索方面的強大能力,使其成為業界的亮點。儘管其安全防護機制對於直接有害內容有效,但對於提示注入的抵禦能力仍有待進一步測試。Mixtral 無疑為構建高效、高性能的 AI 應用提供了強大的基石。